A history of outliners
An inspection of what outlining is, the history of outliner software, and why it appears so valuable.
Outlining is a methodology that structures text into ordered groups of nested blocks. Often these blocks relate to each other by topic or some other semantic. The parent blocks define the generalities of the more specialized blocks they contain. This creates an ordered tree hierarchy of information.

This general idea can range from very large blocks structured by headings and sub-headings in a long-form text, to a note-taking method that cuts everything apart into terse sentence fragments grouped and structured with an expansive bullet list structure.
The uses of outliners are many, but they all relate to the issue that the human brain has limited working memory. The structure of outlining lets us assist our mind in versatile ways.
One way is to plan and schedule: a large task can be cut apart into smaller and smaller sub-tasks, each block being a reminder of what needs to be done, and its hirachy a context of what we are doing it for. This is useful both for writing long-form documents and planning expansive projects.
Another way is to record information. The human mind also likes to stress out about ideas and tasks that it knows have not been properly recorded. This becomes mentally draining. Outliners are able to absorb ideas quickly in whatever order they appear, to then be structured later.
Thus outlining can become a powerful tool to stimulate the free recording of ideas and tasks with less inhibition, as it reduces the irreversible loss of information. And by doing outlining in software, we can empower computers to help us in context recovery and manipulation, shaking constraints of linear text and singular notes.
Because of these properties we find outlining again and again when discussing advanced note-taking and writing tools, intermeshing with the ideas of “tools for thought” and “personal information management”. Those with aggressive note-taking habits for their knowledge, planning, and working innevitably tackle the question of just what systems they use to structure it all and why.
Outliner tools from org-mode to Logseq have some underlying commonalities. They all structure text as blocks, which become nodes on an ordered tree graph. Nodes relate to each other as parents and children between different heights, and predecessors and successors within the same height.
The resulting tree can be navigated and manipulated. Nodes may be promoted and demoted, yanked and pasted, re-ordered, and so forth.
Past this point, you also find ideas like enhanced metadata capabities.
What exactly makes a single block and its contents and how the tree structure may be manipulated, depends on the language and the tool.
That is where this journey begins.
Why I am writing this
Recently I had the pleasure of meeting the cheerful Jacob Zelko over a mutual interest in powerful note-taking tools for locally stored, hyperlinked files. As these things happen, we started comparing systems.
I have been using Obsidian since 2020 to manage my growing notes set. Jacob uses Neovim with a host of plugins. We both use Markdown files as the actual storage files for our notes.
Trying to communicate my system took a while. We both make use of systems that can be called outliners. But our specifics diverged a lot. A question started to form in our discourse: just why was that?
And I didn’t have an answer beyond properties I had found to be advantagous. The exact origin of why indented bullet lists had become this strongly present idea of how to do outlining eluded me.
As me and Jacob analyzed just what outlining did and how people had crafted the systems in software tools, a more thorough explanation started to emerge.
This article is that explanation: a mixture of the advantageous mechanics of outlining for helping human thinking with software and notes, and a historical review of what tools and methods were apparently crafted when. And I present a hypothesis as to the biggest reason why one would want to use such a highly structured, terse note-taking system.
The history of outlining presents itself as convoluted and less straight-forward than one might first imagine. What I discovered genuinely suprised me. And in some ways, it is a discovery of a differnt process entirely: how people created new tools with incomplete information, replicating patterns they liked and putting their own spin on them.
Looking back on history
As a single person, I have a limited overview on everything that has happened arount the concept of outliners. The research starting points was very much colored by the tools myself and Jacob were familar with; and overview articles that have been published by other bloggers.
Yury Molodtsov’s article “The Evolution of outliners” was a jumping-off point for my reseach.
At a glance it is tempting to suggest that there has been a straightforward development of the idea of the “outliner”, but with every bit of research there is less support for such a hypothesis.
The closest definitive evolution I want to suggest is the recent development of “tree-to-graph” tools like Roam Reseach and its descendants and how they started working with bi-directional links. The highly atomic structure with terse sentences combines with the tree structure of the outliner to become a foundation for interesting capabilities — I will expand on this later.
The history of outliners appears to be driven by a mixture of “game of telephone” and “reinventing the wheel”, intermixing with a struggle for common file formats.
Before 2003
To show just how far back the rabbit hole goes: take MORE, a Macintosh “outline processor” from 1986. The system already understood the tree structure and allowed for significant manipulation of it.
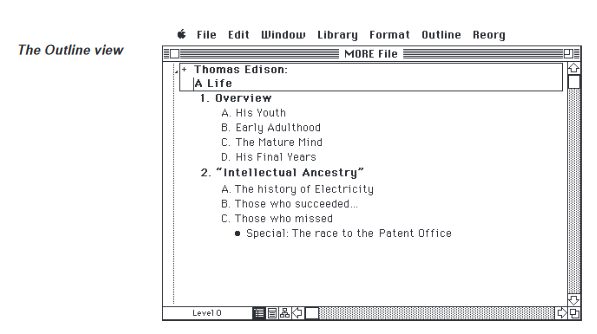
GrandView was a software released in the 1990s, and that software evidently featured significant abilities not just to use a computer to create lists for meetings or writing, but also for sorting lists, and aggregating them using metatada features per node.
The blog “Welcome to Sherwood” has an in-depth retrospective on GrandView including screenshots.
OmniOutliner has documentation from at least as far back as 2002, and this too featured significant capabilities for organizing, annotating and formating the tree structure. To paraphrase their motivation: “Paper is not good, word processors are not made to create lists, and spreadsheets are overkill.”
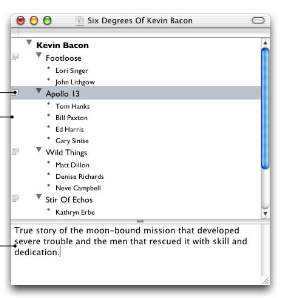
Interestingly, OmniOutliner allowed the users to rapidly mix bullets and tasks and convert between the two. So a user could write out their thoughts as they streamed in, then sort the results out into tasks to do and notes to store. This is a significant choice that reduces friction, since now the user can store the significantly better working memory and flexible data structure to order and assign notes outside of the constraints of their small working memory.
MORE and OmniOutliner stored their data in their own internal file format — to some challenges with subsequent readability. The existence of its rich text format exporting options to “flatten out” the internal data structure makes me speculate that without the software itself, the resulting files would not have been readily human-readable.
Two outliners for Linux that get cited on Wikipedia are TreeLine, a software whose history goes back to at least 2001, and KJots, a tree-structure organizing text editor first released in 1997. Both of these are cited as outliners and technically do support such, but also have much stronger database features and seem less aimed at quickly writing lists-as-trees like OmniOutliner.
The trend of 90s “outliners” to include database features is one of those aspecs that has gone down a bit in comparion in software that first launches in the last two decades, the still-present OmniOutliner and new tools like Tana, aside.
Emacs and Vim
In light of such tools, it is interesting to see how org-mode decided to look at outlining when it was released for Emacs in 2003. Org-mode espouses the idea of outlining inside a single text file using headings. The underlying storage format is a normal text file with a specific markup syntax that org-mode parses out. The result is a tree structure that can be navigated and manipulated: headings can be promoted and demoted in level, moved about, folded in and out to make the UI less distracting. Interestingly, org-mode provides a means to rapidly write multiple headlines in succession using a special key command when creating a newline: this inherits the previous heading level.
Big org-mode documentations suggest that you should first quickly create your heading structure when writing a document, before tackling the bodies under the headings bit by bit.
Org-mode thus created, in comparison to some earlier tools, a new way to go from simple notes and outlines to a single text file product, stored as just that one file instead of a complicated XML or other text file format.
Notably, org-mode retains the ability to interact with plain lists in a similar ordered tree fashion: you can indent and unindent list items including (or excluding) their subitems and move them up and down in the indentation level.
However, org-mode’s ability to navigate is oriented around headings only.
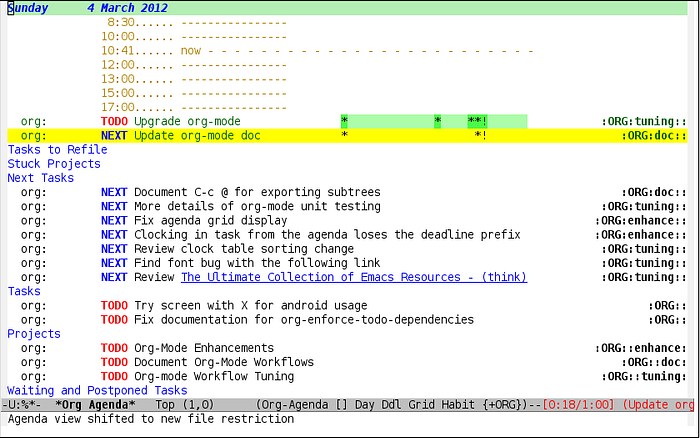
Another interesting feature org-mode has is that it understands tasks and items — any single heading in an org document can become a task item by inserting a TODO string into it. This combines with org-mode’s various abilities to aggregate various tasks built right into the engine — the agenda view is an often-cited feature.
For vim, one outliner tool that stands out is Voom, first released in 2009: it parses an outliner tree from its own “fold marker” syntax or markers of various languages like Markdown and ASCIIDoc. This tree can be navigated and manipulated using various commands, including yank and paste operations as well as sorting. What is interesting here is that Voom can work on any file — the fold markers can be placed as comments inside of a source code file, chunking the source code into an ordered tree structure.
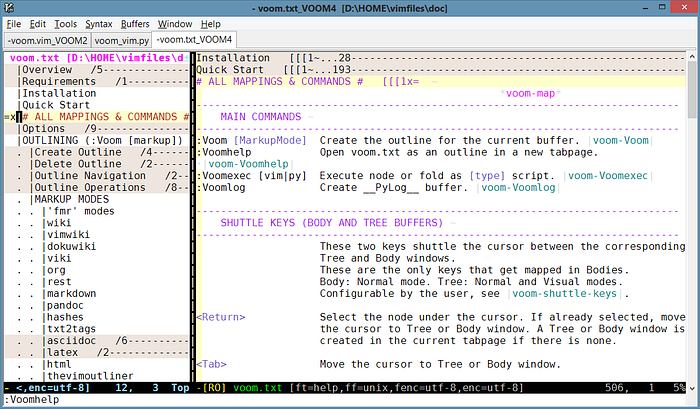
What unifies org-mode and Voom is their ability to work on plain-text human-readable files while providing structural navigation and manipulation abilities that were earlier realized with different file formats using only a GUI. This design choice increases modularity and interoperability, as well as creating redundancy — even if a specific implementation dies, another tool can take its place and read the data — and a fast fallback, any text editor and the plain human eyeball suffices.
The power of this choice shows itself to this day: formats like org-mode and Markdown, which can have their tree structures parsed out by editors when opened, are leveraged by other editor and information storage systems for this reason.
The modern bullet editors
A big design pattern we see in the current tools appears to have come about with the introduction of Workflowy in 2010 and what followed in its wake. The earlier tools were a mixture of custom file structures, plain text with formating conventions, and open data structures like XML and OPML. Some of them grew into full-on databases with metadata colums, becoming “Personal Information Systems”.
Workflowy
Workflowy threw a lot of that complexity out, but kept the idea of its own file format and a generic tree that could grow indefinitely. A user’s notes across everything became one large, endlessly growing tree structure. “Folding” was replaced by “zooming” to particular nodes and all their children on the graph.
Workflowy had a background in frustration about existing project management tools. It pushed terse notes you could make quickly to the forefront of the user experience. The “bullet” became the agnostic representator of the endless tree structure, with its simple style allowing it to be used arbitrarily by the user to create flexible structures without the visual appearance getting in the way.
In the wake of Workflowy experiencing a development slump
came Dynalist in 2015. Dynalists worked from the same concept of an endlessly growing tree, but pushed in some advanced features.
Roam Research
Then came Roam Research in 2017.
A lot of the contemporary ideas that define the workflow I use com from Roam Research, and ideas from that software have spread onwards and backwards to other tools.
The big thing Roam appears to have pushed to the forefront again were links between nodes, all while empathizing a basic theme of “low friction”.
The foundation of Roam notes is still an “every paragraph is a note” thinking like Workflowy, but “files” create easily referenced graph sections which can be linked to with a simple link syntax, right in the text. Creating a link to an existing or a new file is almost as simple and fast as just typing text.
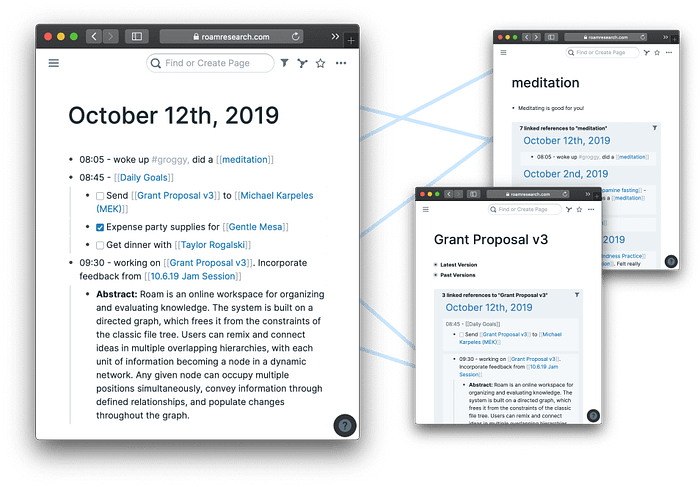
Roam uses these links to build automatic backlink listings. A classical wiki does not show you what other pages link to the current page. Roam does, in a list found at the bottom of every page.
Users could now turn the graph into a tree, breaking up the strict global hierarchy with links from and to any node. This combined the powers of outlining for fast local structures with the nature of most information: it has multiple contexts and does not fit into just one strict hierarchy. Furthermore, the automated listings make it easy to grasp what other notes, what other context, find the current note relevant.
Combined with its daily notes journals, Roam arguably defined the modern idea of the opiniated yet flexible, low-friction tool. If in doubt, thoughts and tasks can all just be written down in the daily notes first. A simple backlink mention to the concepts or project names or sources relevant to those daily notes suffices to make the entries in the daily note visible at a glance in the linked notes. The user did not have to worry about properly locating their entries immediately on capture; indeed most of the way would happen automatically.
Logseq
Logseq took these ideas in 2020 and turned them into an open-source project running on local org-mode or markdown notes. We come somewhat of a full circle with this. Workflowy, Dynalist and Roam are online tools running in the browser. Logseq curved back to the likes of org-mode, with no internet dependency. It kept the core workflow of Roam however, where everything was terse notes and a background database automatically aggregates and presents backlinks on every page.
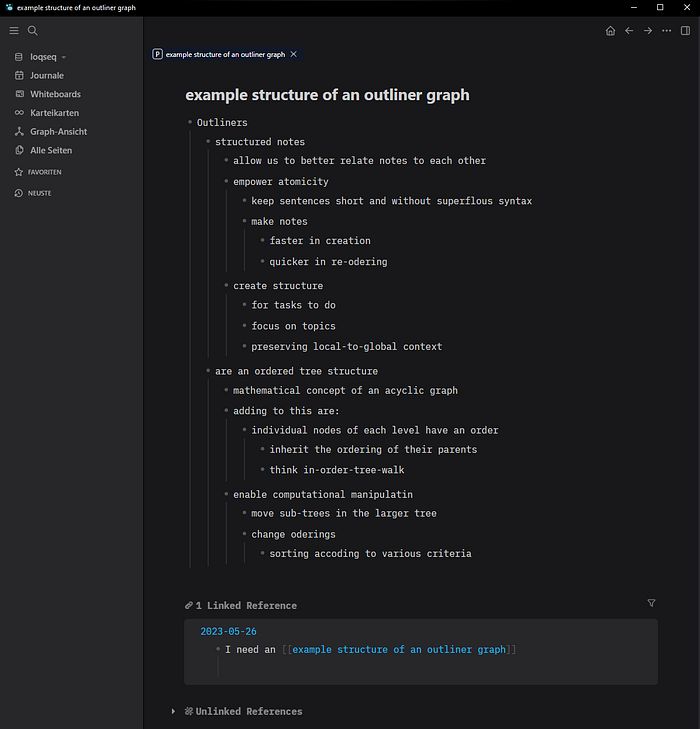
From my overview, when people talk about Outlining these days, they will usually refer to either Roam or Logseq (and contrast them with Obsidian). Roam has been hugely influential in the modern knowledge management space, and big discussions just kind of innevitably curve through its field of influence.
Obsidian
To mention the asian elephant in the room. Obsidian isn’t usually considered an outliner. However, the current version support outlining in many ways like Voom or org-mode do: Obsidian builds a tree structure of all the markdown headings in the document. It allows collapsing headings for focus, and drag-and-drop changes to the outline in an overview pane.
With community plugins, many of the features found in other tools can be loaded into Obsidian. The Outliner plugin turns the Markdown unstructured list into a manipulatable tree structure with movement, promotion and demotion of subtrees, similar to modern org-mode or Logseq. The influx plugin supports building Logseq-styled bullet lists. Hover Editor lets you edit from note hyperlinks, though not in the same style as how Logseq lets you edit right in query printouts.
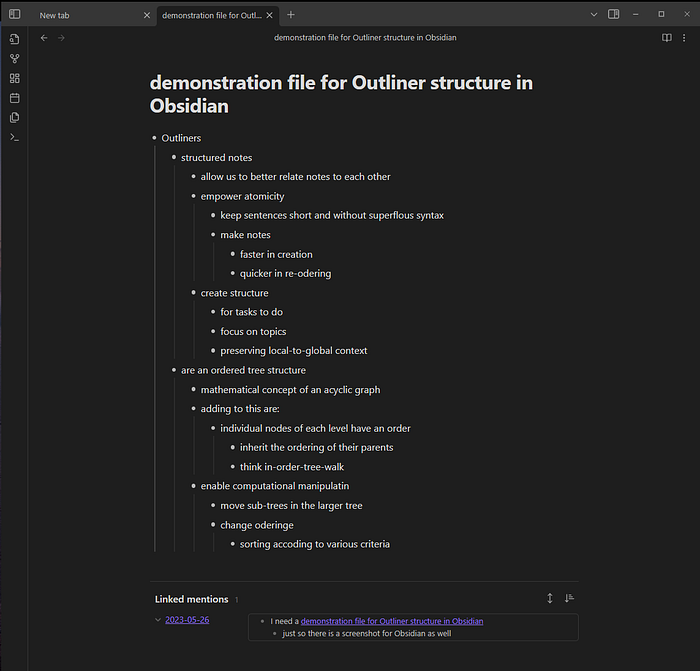
That said, Obsidian remains a long-form editor at heart. Queries are designed differently, and how backlinks and references are resolved differs.
So why bullets?
To go back to the land of purposes from the land of histories decades old as well as recent: the purpose of outlining is to bring structure to notes.
This structure has a lot of implications. You can zoom into just parts of it, removing the irrelevant bits from your perception and avoiding overload.
You can find your context quickly by checking the information of the parent nodes from where you are working.
You can record first, reorder later, because the structure is highly malleable and adaptable.
You can always add more thoughts to any existing nodes by adding child nodes, displacing the content below.
And if you take your notes in a style that uses very terse sentences and leans on the structure to communicate how these block together into larger semantic units, you can profit further from the ease of re-ordering and extending things. There is always room to re-think and add another thought.
But none of this really needs bullets. org-mode headings are only as fancy as your conceiler config, and Voom fold markers aren’t fancy at all (if a little tedious to type).
The app that pioneered what I think is the killer feature of the highly atomic, terse note-taking tree, didn’t think in bullets on a text document at all.
Roam research uses a database for all of its notes. There is no local text document underpinning the nodes.
Roam’s big feature (and from them, Logseq and other apps that offer the same UI) are its automatic backlink aggregation. At the bottom of every page you see the [[wiklinks]] from other pages to that page. That lets you grasp how the page you are currently on links to other notes, which is key to supporting associative linked thinking with a note-taking tool.
But just a list of what page links to where you are at is pretty useless for grasping the context of the link. Roam encourages just adding links everywhere, so the links will be embedded into text.
So you need to also show the text that is around the node. The sentence at least, maybe better the paragraph.
But is that enough context? In a free-form text document, the previous and next paragraph might also be relevant. Maybe the following three paragraphs are all part of one block of logically connected thoughts. There is no way for the software to tell.
There is, however, in the highly structured format that Roam encourages its used to write in. The child tree of any node is reasonably some type of deepening context: so you transclude all of that together with the node that contains the link.
The end result is an automatic aggregation of context from all notes in the workspace, accessible at a glance. By making the transclusions of the backlinks editable, Roam also lets the user reach directly into those other notes again to edit or extract notes; while having the accumulated context of all the other notes as well.
This way of reframing content in the tree in new ways automatically, just by the user linking to a note (or mentioning it vertabim without a link, through the “unlinked mentions” feature) is another piece in the idea of “low-friction note-taking”, alongside features like making nodes easily converted into tasks, allowing swift addendum notes to any other piece of writing with little fear of breaking structural semantics, and allowing reorganization. Again, swifter human thinking is enabled.
Logseq took this idea and turned it into a locally-first editor. They needed to decide upon ways of storing the database information in the backend. They chose both org and markdown files as supported languages.
That meant mapping a document’s tree content into these formats. For org, they actually chose org-mode headings! So a deeply nested Logseq trees turns into a lot of *. See this example:

The file storage of this is:
* What does this look like under the hood?
** is it a different heading now?
:PROPERTIES:
:heading: 2
:END:
*** what does this structure look like underneath?
**** will they be bullet lists or headings?For Markdown, they chose the markdown lists, possibly in part because markdown headings have a specifications-limited depth and because markdown headings will generally be rendered with much larger fonts.
So my use of the Markdown unordered list to model outliner trees… is an artefact of a long game of telephone, jumping back and forth across different file formats and implementation designs. Structures in text files turned into endless trees in databases, then back into locally stored files wrapped by the UI.
And the specific notion of taking even very large notes in a highly atomized, terse tree-style note-taking system works towards a context retrival system that doesn’t exist in Obsidian’s core. (It can with plugins like Influx. Also, Obsidian block references in notes consider the bullets inside a block as part of the transclusion, so an explicit transclusion link to a block reference will show all grouped context.)
Are there other advantages?
I have repeatedly mentioned the capacity to rapidly re-organize and expand the outliner tree to better capture information. I think this is part of a slew of minor features that overall combine to make outlining a powerful mental tool.
Outlining notes in bullets are visually calm yet ordered. Combined with having the context captured on the page, this combines into an organizing UI without overloading formating; a neat feature for some. All other formating of a language is available and can express itself concisely in addition to the structure.
To quote ink-and-switch, there is a “power to text”. The (indented) bullet list is a universal concept, which translates well from app to app and can be manipulated with minimal fuss even in a barebones text editor that doesn’t actually understand the tree structure in a programmatic sense. Changing a JSON tree representation can get much more tricky. The bullet list also transforms well into other structures such as HTML with minimal fuzz and custom code work.
In Obsidian itself, the use of the bullet as the outliner allows outlining to exist separate but together with free-flowing text and advanced formating. Structure is optional. This is a good thing. A theme that has underlaid all of these explorations is how powerful note-taking tools become when they let the user act with low friction. Being able to start where you want and create structure how it suits you, slots right into that. This article started as an Outline in Obsidian, which then became the flowing test you now read — and both are linked to the project note that guided the creation of this article, right there in one system.
Does that make Outliners the only choice?
That depends on what you want to achive. Outliners are very robust tools for working with streams of thought and limited human memory. They allow us to bypass the limitations of our working memory by creating an external structure capturing context and relations.
But that only works if the information structure we are creating is permissive to such. Many relations are not nearly as cleanly fitting together into blocks of a single outliner note.
Sometimes the power of the modern multi-document linked note editor helps us — a single thing appearing in many contexts can be modelled as a linked note, its content resting in a single point and only being linked to from elsewhere.
We should remember why we build software this way: because it captures a way our minds model information relations. Sometimes the only way to grasp a concept is to build that complex associative network in our heads, the same way a software parser turns a linear stream of information into a graph.
The use of linear text, that slowly over time builds up the nodes of information and their relations to one another, will sometimes just be without option.
And sometimes the high structure of the outliner is in itself an obstacle. A lot of methdologies for digital notes are about interpretation, evolution and synthesis. That means finding novel perspectives.
In the Zettelkasten system, expression in your own words is reinforced by many tutorials and theorists because it forces our brain to engage, understand and express the Information more thoroughly than a copy and paste.
Richard Feynman’s highly effective method of learning a topic involved repeatedly working to communicate the information until it could be expressed clearly to a four-year old.
Yes, human memory and minds are fuzzy. We confabulate, we fill in “good enoughs”. But that way lies novelty. Sometimes, forcing our mind to rebuild the relationship system from scratch with the uncertainties and compromises involved, produces good things.
Thus the long-form text synthesis becomes an expression of true idea evolution. It takes relations and compresses them, it places empathis and invites novel interpretation and re-relation.
And all of these artefacts should just as much be part of a note-taking system as the highly structured, atomic outliner.
In the end
Behind the history of the outliner lie many, many valuable lessons. It’s a decades old idea that has been re-interpreted again and again and will be interpreted again and again going forward. It is a not-so-small microcosm of everything around digital note-taking and “tools for thought”: a constant evolution in time as people identified needs and created the tools to meet them — and in creating these tools, understood themselves better too.
There are more lessons to be drawn from this history. I have only scratched the surface. There are many more outliners, structured note-taking systems, “lightweight wikis” out there.
But the lesson under this all I would like to keep in mind the most is: keep the friction low. The better we let our tools capture our thoughts in whatever shape they come, and the better we let our tools evolve those records in whatever shape we want, the better we can use them to drive our own thinking forward. Because in the end, the notes are the records. The graphs are transient. All of it is an expression of what we are thinking, inside; a state which we move forward every time we engage. And if you do not work from there and towards there, you will always find that friction again.
(Where we can go from there, is another exciting dicussion entirely.)
If you read until here, thank you for going on this journey with me. I hope it was informative and has given you new perspectives and new impulses to work with and maybe share with the world. I would love to hear your thoughts, information, feedback and corrections.
Until next time.
